Introduction
So far in this AT 319 class, it has been focused on gathering imagery in nadir format, which is a great way to produce orthomosaics and Digital Surface Models in bundle block applications. However, nadir images do not too well in capturing vertical objects. Producing 3D datasets that are applicable to GIS is currently a strong market trend. Therefore, and since the geospatial world is moving towards being entirely 3D, this is an important aspect to learn. This lab will focus on processing oblique UAS imagery gathered for 3D processing. An introduction to Image annotation will be made. This feature basically removes unwanted background content, will be cover beneath.
The reason why oblique imagery is collected at an off-nadir angle is that one can see and measure the side and top of objects. Oblique imagery contains loads of another type of information which traditional aerial photography lacks. Notice the difference in detail between the oblique and nadir imagery. But both have their advantages and provides the user with distinctive information. The images below show the central parts of Oslo, Norway.
 |
| Figure 1: Nadir viewing |
 |
| Figure 2: Oblique viewing |
Image annotation
In images in general, there almost always exist unwanted objects, called noise. But do not mistrust, there is a remedy, namely a feature called annotation, which helps to remove the noise. A good example is by looking at the sky in oblique images or backgrounds in general. The image annotation feature in Pix4D itself takes place between steps 1 and 2 of the whole 3D Model image processing. The annotation is a pretty tedious thing that takes a lot of time. The best way to annotate is to start zoom fully out and scroll around the desired object and keep holding the button down so all desired clusters get annotated. Get as close as possible without risking hitting the object, then move on to zoom in and continue annotating the more indistinguishable clusters. Also, another tip to make the annotation faster is, if there exists a pattern in the image, move the cursor across it instead of along cause it makes the clustering process go faster. Remember to annotate enough images, 6-10, with as big variety in angle as possible.
There are three different types of annotation in Pix4D, namely Mask, Carve and Global Mask.
Mask annotation would apply for removing obstacles that appear in a few images. It could also be used for removing the background or the sky automatically.
Carve annotation is used to remove 3D points directly in the rayCloud, based on fast annotation of pixels on the images. Annotated pixels are deleted. This one is used if one wants to remove the ground for instance.
Global Mask annotation is basically like Mask except that the pixels annotated are propagated to all of the images. It is suitable to use when one has a constant obstacle on all images.
Methods
Normally, when creating a new project, be cautious to choose correct Datum and Coordinate System. Since there was no metadata this time, I chose automatic detection, information gathered from the camera.
 |
| Figure 3: Choose correct Datum and Coordinate System |
 |
| Figure 4: The goal for this week is to create a 3D mesh, thus choosing a 3D model. |
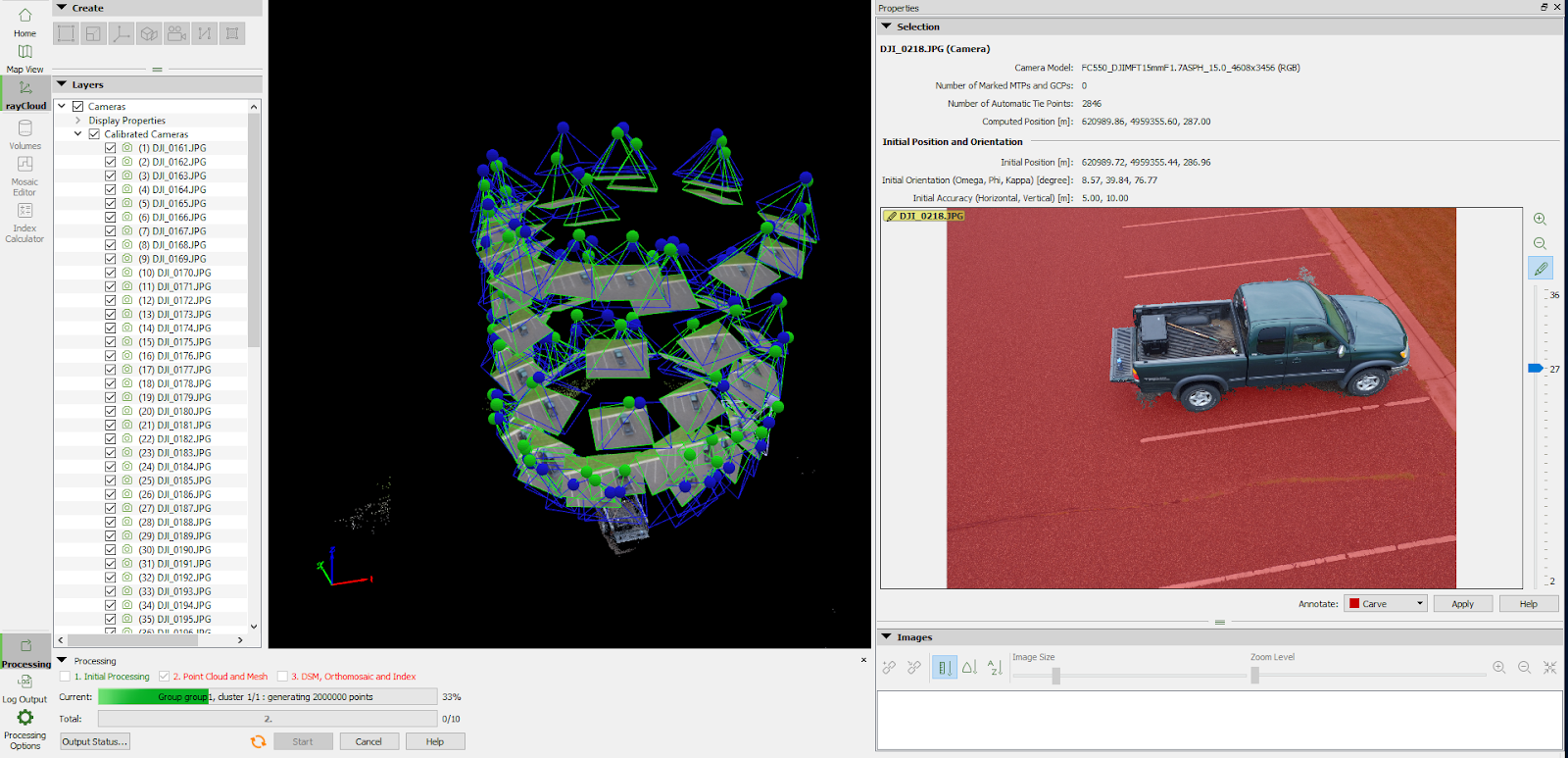
Dataset 1: Joes Truck (based on 69 images) and 6 images were annotated with Carve.
In the first initial process, the key points are computed and tie points are analyzed. Like previously stated the annotation itself takes places in between the first and second step of the entire 3D modeling process. The annotation is a process to filter out the unwanted pixels and the figures below illustrate information about how to do it.
 |
| Figure 5: Annotation with the imaged zoomed out. One can see clusters scattered around the truck. |
 |
| Figure 6: One image partially annotated. The hardest pixels to annotate are the ones that are close to the truck for obvious reasons. One does not want to carve out parts of the truck. Therefore, while doing the most detailed parts, the image should preferably be zoomed in. The more accurate this carving session is, the better the result in the end. |
 |
| Figure 7: One image fully annotated. |
 |
| Figure 8: After annotation, start the second step in the process, the Point Cloud and Mesh. |
After the second step of the whole process has finished it creates a point cloud and a 3D mesh. Below are first the results of the Point Cloud and the 3D mesh of the truck. In the Discussion section, the results will be articulated further.
 |
| Figure 9: The point cloud |
 |
| Figure 10: The 3D mesh of the Truck from the left side. |
 |
| Figure 11: Truck from the right side. 3D mesh. |
 |
| Figure 12: Truck from above looks like it could have been a 2D image but is not. This only displays the carving of the background was made properly. 3D mesh. |
 |
| Figure 13: Still not perfect, this mesh (the point cloud has been removed) is a good quality, where even the name of the vehicle could be seen. Spoiler alert: Toyota Tundra. |
Dataset 2: Light Pole (based on 33 images and 9 images were annotated with Carve.
I will now create the same process for another dataset that includes another background. A background that has a higher contrast to the object than the other. To distinguish the dark grey/blue truck from the asphalt was not so easy. I expect it will be easier for the software to differ a white light pole from its mostly green background. This dataset does not contain any sky, but in general, the sky does not contain any meaningful key points. The carve annotation is especially practical for images with skies since all the 3D points that are located in a line with the rays connecting the camera and the annotated pixels are deleted. Initially, I will use mask annotation and afterward use the carve annotation. This was done on the same dataset to illustrate the differences between the two options. Below is the UAV flight pattern around the light pole.
 |
| Figure 14: The flight pattern around the light pole. |
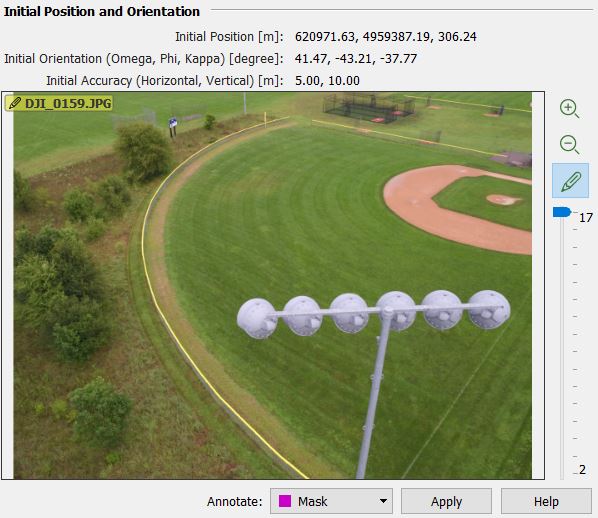
According to Pix4D, the taken images from the second dataset says it ranges from 306 meters to 314 meters. To me, this sounds like feet but the figures below illustrate meters.
 |
| Figure 15: The image that was taken from the highest position. One can see here that a part of the pole is covered by the lights. Could this possibly have an effect on the result... |
 |
| Figure 16: The image that was taken from the lowest position above the ground. |
 |
| Figure 17: Like expected, it was easier to mask a white light pole from its mostly green background. |
 |
| Figure 18. The same image zoomed out. |
 |
| Figure 19: Even this picture, the mask annotation worked good. |
 |
| Figure 20: After the annotation is finished, step 2 can start for dataset 2. |
 |
| Figure 21: With mask annotation, the ground still shows. |
 |
| Figure 22: Like this and next figure show.... |
 |
Figure 23: ... the quality was not that great.
|
 |
| Figure 24: This is after both the point cloud and the mesh is produced. |
As one can see, the pole covered some parts of the pole, which is the reason for the result above.
Like mentioned above, in order to differentiate between the two annotation options, I decided to do the work over the same light pole dataset again but this time with the carve annotation instead of with the mask. My goal is to make the background removed and only keep the object.
 |
| Figure 25: In the progress of carving one of the 9 images |
 |
| Figure 26: Another image, fully carved. |
If there is not enough point cloud data, it will affect the whole 3D model. This is especially obvious on thin objects, like this light pole for instance where there weren't enough data to successfully create it. A reason that the lower 3/4 part is visible, is that the chosen imagery covered those parts. However, the other 1/4 was not covered from every angle and that is what the figures below demonstrate.
 |
| Figure 27: Point cloud data of the light pole |
 |
| Figure 28: Mesh of the light pole. Not so much difference on this dataset. |
 |
| Figure 29: Point cloud without meshes, zoomed in. |
 |
| Figure 30: Point cloud data with meshes, zoomed in. |
 |
| Figure 31: Look at the angle that this image is taken from and how the lights cover the pole. This is the main reason the result gets like it was. In order for this not to happen, further images that do not cover the top 1/4 of the pole should be used. |
Discussion
When performed the carve for dataset number 1, Joes truck, I was deliberately choosing an image from a wider angle at the right side of the truck than I did on the left side of the truck. 6 images were annotated with carving for dataset 1. This gave me an option to see the difference by having the asphalt being carved out beneath the car. This is well displayed in figures 10 and 11.
Image annotation removes unnecessary and unwanted point data, hence one would like to choose what NOT I to have in an image. The processes of carve and mask away all the data in the point cloud that is unwanted takes a lot of patience. As the results above illustrate the more accurate the annotation process is, the better the result. The good part for the first dataset is, of course, the high details that were generated. In order to improve this further, images from different angles and height could have been selected to annotate. Removing unwanted features from under the car is a problem though since the UAS not so often get angles of that high values. If needed, it is possible to go back and annotate further images, reoptimize, and run the processing again. In order to save time, I run step 1 and 2 separately with the annotation baked in between.
For the second dataset (Light pole) the situation was a little bit different. Mainly it did only have about as half as many images to produce a point cloud and a mesh but also it had a background that had a higher contrast to the object than dataset 1 (Joe's truck). Since the images with the white light pole had a green background (in terms of grass and bushes) it was easier to distinguish than the dark grey/blue truck from the asphalt in dataset number 1. I assume it would be equally easy to carve and mask skies as it was with these backgrounds. That would be interesting to investigate. 9 images were annotated with masking for dataset 2.
Unlike the object from the first dataset (Joey's truck), the light pole was so much thinner and not so many point cloud data generated. This could be a reason that it did not show the entire pole up to the flag. Therefore, especially on thinner objects, where there lies a risk that chosen imagery miss some parts of the object, there should be an increased amount of images annotated. I chose 9 images for the light pole and tried to choose images from different angles and height but still, that was not enough to catch enough data on the pole. Below is the video result of the second dataset, the light pole. Below are video results for the first and second dataset.
Conclusion
Just like the first two figures in this lab displayed, data gathered straight from above (90 degrees, nadir) does not tell everything. By using oblique images further details can be attained, as well as more background can be carved out in the annotation process. The result does not get better than the basic data gathered, thus, collecting data from different angles is key.
Like mentioned earlier, when 3D modeling thinner objects are some additional risks. If the user happens to choose images taken from typically the same angle, parts of the object may not be identified and reduce the quality of the project. What also goes into the book until next time doing practices like this is to use an increased amount of images. When I chose 6 images to annotate for Joe's truck and 9 images for the light pole I tried to pick the images from different angles and height. For the truck it went okay but for the light pole, that was basically not enough to catch enough data. However, the number of images is overshadowed by the importance of using images with different angles. To sum it up, using both nadir and oblique images would have generated the best results.





























wow this is very detailed and thorough. Nice!
ReplyDeleteWow! Thanks buddy :)
ReplyDelete